Animeloop 网页服务器开发细节
这篇文章主要记录了在开发 animeloop server 的过程中遇到的一些问题和相关的解决办法,以及整体服务器程序的结构设计。
基本结构
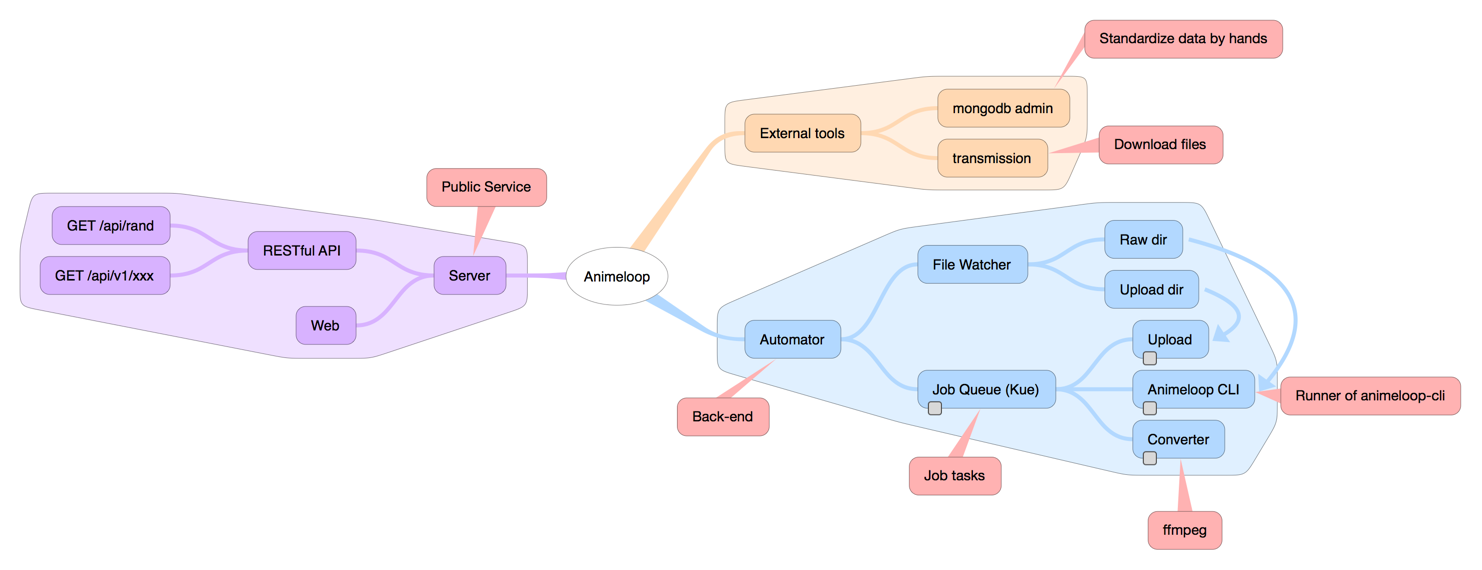
图片生成于 iThoughtsX for Mac
数据库
Animeloop 服务器数据库一开始是使用的 MySQL 的,但是后来为了尝试新技术方便,改用了 MongoDB。我个人的想法是,这种不包括用户数据的站,其实是并没有多少数据量,(对比一些社交网站,可能用户会发大量的文字或者上传大量的图片),所以~~从偷懒的角度来讲,~~至少开发前期是完全不需要考虑性能问题的。使用之前在网上也搜索过相关的信息,比如使用 MongoDB 的优缺点,MongoDB 和其他数据库的对比之类的,实际上在我看来就是“不存在的.jpg”。
据我目前了解到的知识,使用 MongoDB 的话,其实是可以直接粗暴的往里面丢数据,而不需要考虑分表和建立相互之间的关系的。你可以从前几次的代码提交中看到早期数据库 Schema 设计是没有像 。series: { type: ObjectId, ref: 'Series' }, 这种的 ref 引用的。(嗯,现在暂时闭源了)
一开始整套网站(不仅仅只是前端界面,包括服务器甚至数据库建表相关的代码)全部的代码开源,但是后来我意识到自己想要把这个站做好,也不想被人恶意的复制站点,所以选择了暂时性的闭源。现在还在考虑要不要只开源前端以便有更多的人参与到开源开发中。(假装有人愿意一起开发
但是这样一来在开发 view 的时候就遇到一个问题,如果没有给 series 和 episode 建表(也就是 Mongodb 里面的 collection)的话,前端访问页面的时候就不能像 GET https://animeloop.org/series/:id 这样来访问了,因为没有 collection 所以也就不存在 id 了。而且不能直接把 title 放进链接里面,因为早期根本没有考虑国际化, title 直接存入的中文(链接里面带有中文字符有时候会出现问题)。(现在后悔了,应该用英文 title 作为主键的)
const SeriesSchema = new Schema({
title: { type: String, unique: true, require: true },
title_english: String,
title_japanese: String,
start_date_fuzzy: Number,
// ...
type: String,
anilist_id: Number
});
const EpisodeSchema = new Schema({
title: { type: String, unique: true, require: true },
series: { type: ObjectId, ref: 'Series' },
no: String
});
const LoopSchema = new Schema({
duration: Number,
// ...
episode: { type: ObjectId, ref: 'Episode' },
series: { type: ObjectId, ref: 'Series' },
});
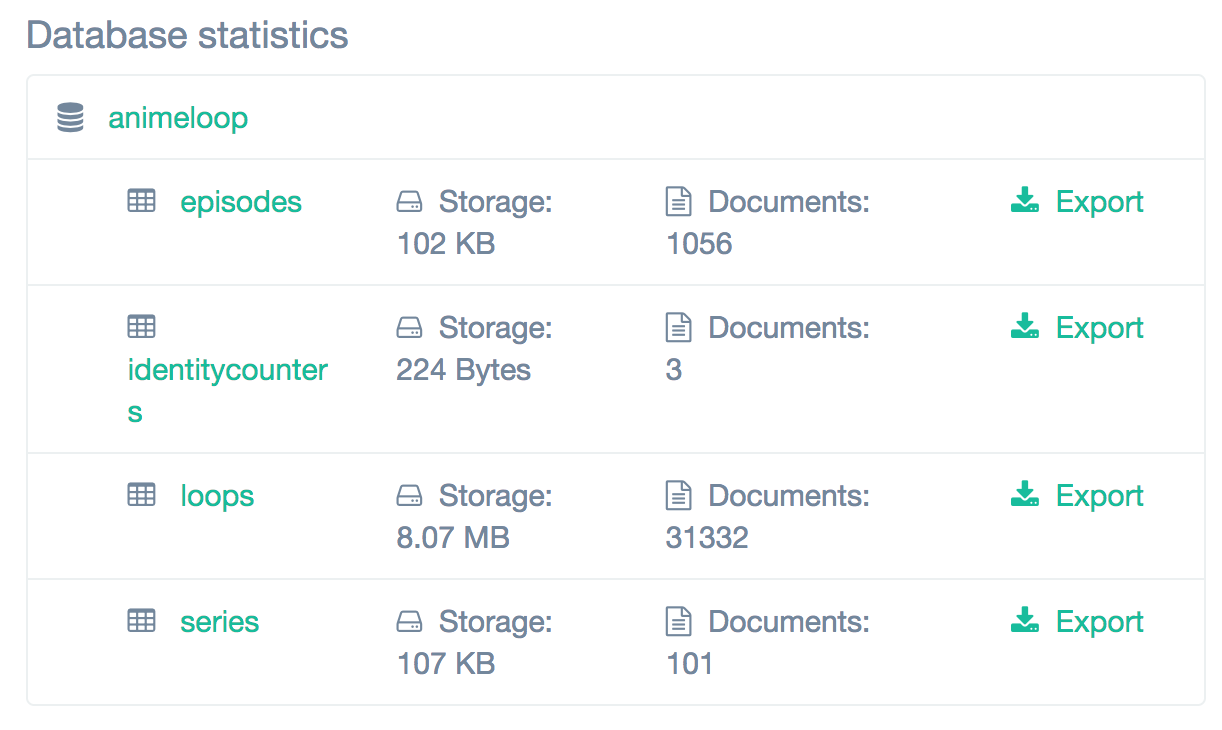
截止 2017 年 6 月 20 日,Animeloop 数据库统计情况
自动化的任务调度
Animeloop 的数据主要是通过程序生成的,自然也就是需要考虑到自动化。

图片生成于 iThoughtsX for Mac
目前 Animeloop 生成数据的整套流程(Workflow)大致如下:
- Transmission 下载 1080P 的动漫生肉文件,在完成的时候移入 raw 文件夹;
- Automator 监听 raw 文件夹,一旦有新的文件加入,运行 animeloop-cli,得到的数据移入 upload 文件夹;
- Automator 监听 upload 文件夹,有新的文件加入,随机获取截图,并通过 whatanime.ga 获取相关的信息,比如动漫的标题、时间、类型和 anilist_id 等,之后通过 anilist_id 在 anilist.cc 站点获取更多的信息。
- 执行文件格式转换,输出目标包括不限于 360P mp4 webm gif 。
使用 whatanime.ga 接口
whatanime.ga 目前的识别率其实是比较高了,但是为了尽可能的提高准确率,这里的实现方式是随机拿到三个 loops 的视频封面截图,向 whatanime.ga 请求三次识别,返回的数据取其中两个以上相同的数据,如果没有符合条件的,series 字段设置为 DEFAULT SERIES, episode 字段直接设置为生成数据用的源文件名。
当我把识别次数提高到 5 次——也就是同时识别 5 个 loops,判断是否有三个及以上相同结果——的时候,已经基本不会有错误的识别了。(除非是 whatanime 本身的识别错误)
另外,在尝试把 OP 部分去掉之后,识别效果更好了,大致算了一下,可能 5 部不同的番剧总共 60 多集的识别才会出错需要手动纠正。(当然,个人番剧不算,识别率很低应该是 whatanime 那边出问题了)目前的代码实现是直接粗暴的去除掉在 00:00:00 ~ 00:03:00 这个时间段的所有 loops。(至于为什么不是 00:00:00 ~ 00:01:30,有些番剧 OP 不一定在最开始播放,实际上我个人感觉现在大部分的番剧都不会在一开始就播放 OP 了。 有去找过 提供 OP/ED 时间点的网站,但是没找到。)其实 ED 也应该去掉的,但是因为 animeloop-cli 生成数据的时候没有提供一集视频的总长度,所以不好判断 ED 的时间段。
series 字段设置为
DEFAULT SERIES,因为目前的网站没有做后台页面,对于数据库数据的修改维护都是靠手工进$mongocli 修改。如果每一个无法识别的项目都有不同的 series,维护的时候每一个 series 都得手动删除。
考虑到 whatanime.ga 还有请求频率限制,还需要在请求的时候加上一个延时,保证不会有高频率请求出现。
var randomLoops = loops.slice(0).sort(() => {
return 0.5 - Math.random();
}).slice(0, 3);
async.series(randomLoops.map((loop) => {
return (callback) => {
setTimeout(() => {
whatanime(loop.files.jpg_1080p, callback);
}, 5 * 1000);
}
}), (err, results) => {
// error handle
results = results.filter((result) => { return (result != undefined) });
// error handle
var counts = {};
results.forEach((result) => {
counts[result.anilist_id] = counts[result.anilist_id] ? counts[result.anilist_id]+1 : 1;
});
var result = undefined;
for (let key in counts) {
if (counts[key] >= 2) {
result = results.filter((result) => {
return (result.anilist_id == key);
})[0];
break;
}
}
if (result == undefined) {
loops = loops.map((loop) => {
loop.entity.series.title = 'DEFAULT SERIES';
return loop;
});
callback();
return;
}
});
文件操作的注意事项
注意文件操作的原子性。举个简单的例子,比如从 1080P MP4 到 1080P Webm 视频格式转换的时候,中间过程可能会被中断,但是还是会得到一个不完整数据的输出文件。简单解决的办法就是使用一个 temp 文件夹,在程序运行写文件的过程,先写入到这个临时文件夹,在确认运行成功之后再移动到最终目标文件夹。
这套服务器程序对文件操作的一些处理:
- Transmission 下载文件的时候会先下载到 incomplete 文件夹,当整个任务下载;
完成,再自动移动到 complete 文件夹;(Transmission 本身就有这个功能) - animeloop-cli 在缩小视频尺寸(resize 32x32)的时候、输出缓存哈希文件(dHash、pHash)的时候以及输出循环段文件的时候,使用临时文件夹;(暂未实现)
- 格式转换的时候使用临时文件夹。
极其重要的错误处理
实现自动化极其重要的一点,错误处理。也就是说,像 try {} catch {} 和 if (err) {} 这种情况,绝对不能无视。
日常开发一些小软件或者小脚本的时候,可以忽略这些错误,但是不能将这种习惯带入一个比较完整大型的项目里面。
自动化的尝试,让我真正意识到了 Error Handle 的重要性,一套自动化流程 (Automator Workflow) 仅仅是能够跑通是完全不够,因为这只是无数种情况当中能够成功运行的一种,只是在这套流程中有任何的一丁点错误,可能都会导致整套流程的崩溃,甚至产生无法恢复的数据破坏(如果涉及到文件操作的话)。
一开始做这个的我毫无疑问是 naive 的,早期的开发版本在线上跑基本是俩小时一个小崩溃,一天一个大崩溃,甚至到整套系统相对稳定的现在我还有时常连上服务器看系统状态的后遗症(笑。
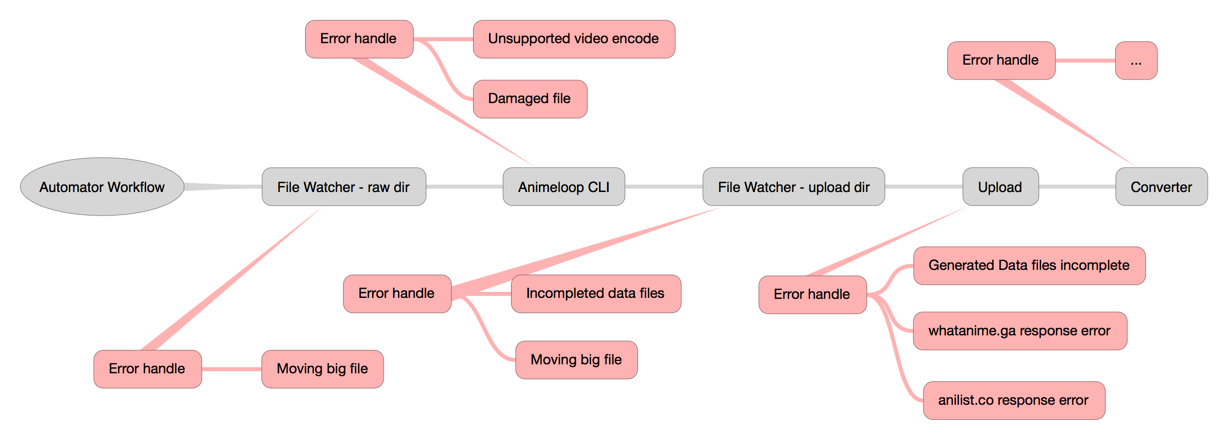
图片生成于 iThoughtsX for Mac
这套服务器程序对运行错误的一些处理:
- 几个文件夹监听,如果读写速度较慢,在拷贝大文件的过程中,可能文件还处于拷贝数据的状态,而文件监听已经响应并且开始执行相应的回调函数操作了。比如下载好一个 20GB 的剧场版动漫文件,在从 incomplete 文件夹移动到 complete 文件夹的过程中,animeloop-cli 已经开始运行了。解决办法就是在监听文件改动的回调函数里加上延时;
- 运行 animeloop-cli 之前,检测源文件是否有损坏,运行完毕之后,检测生成数据的完整性;
- 添加到数据库之前检测数据的完整性;
- 请求 whatanime.ga 时可能的频繁请求的暂时性 Abandon。
- 请求 anilist.co 时可能的无数据返回。
任务调度
这套自动化流程的实现依赖于 Kue 的使用,Kue 是一款 Node.s Job queue 的开源框架,用于对任务的调度。
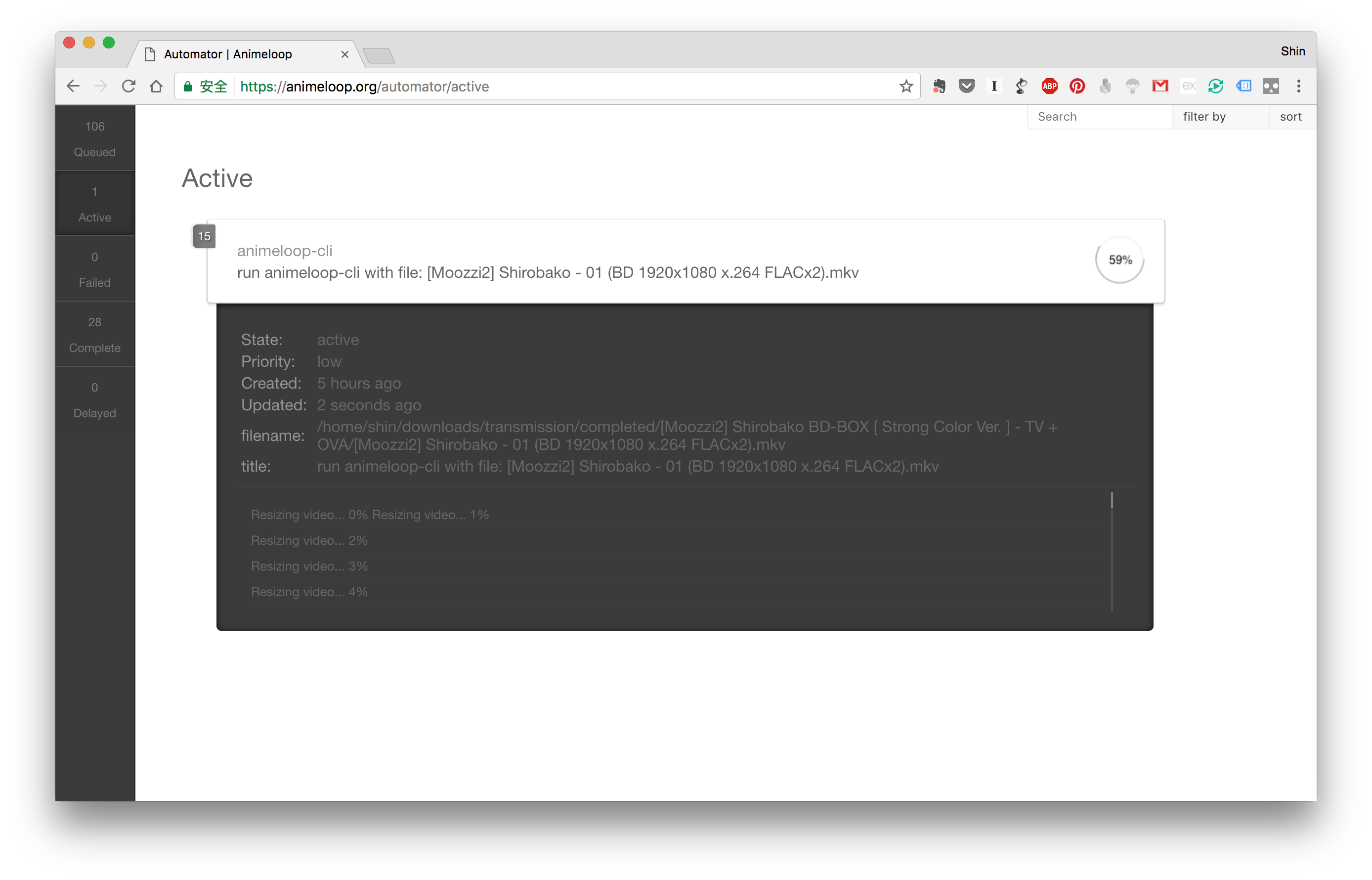
Kue 实际使用过程中发现还是有不少 bug,使用这个框架是因为一开始在 Google 上搜索的时候只找到了这个,应该是搜索关键字的时候没有用正确的字段,后来用
job queue搜索了一下直接找到了三个 Node.js 的任务调度库。本来准备换用其他的还在持续更新维护的库,但是一直也没找到机会。所以先暂时这样吧。
视频转换
ffmpeg -loglevel panic -i ${src} -vf scale=-1:360 ${tmp}
ffmpeg -loglevel panic -i ${src} -c:v libvpx -an -b 512K ${tmp}
ffmpeg -loglevel panic -i ${src} -vf scale=-1:360 -c:v libvpx -an -b 512K ${tmp}
convert -quiet -resize 720 ${src} ${tmp}
convert -quiet -resize 360 ${src} ${tmp}
GIF 转换参数参考:High quality GIF with FFmpeg http://blog.pkh.me/p/21-high-quality-gif-with-ffmpeg.html
对 gif 格式转换的特别处理
pat=palette.png
ffmpeg -loglevel panic -y -i ${src} -vf "fps=10,scale='if(gte(iw,ih),320,-1)':'if(gt(ih,iw),320,-1)':flags=lanczos,palettegen" ${pat};
ffmpeg -loglevel panic -i ${src} -i ${pat} -filter_complex "fps=10,scale='if(gte(iw,ih),320,-1)':'if(gt(ih,iw),320,-1)':flags=lanczos[x];[x][1:v]paletteuse" ${tmp}
rm ${pat}
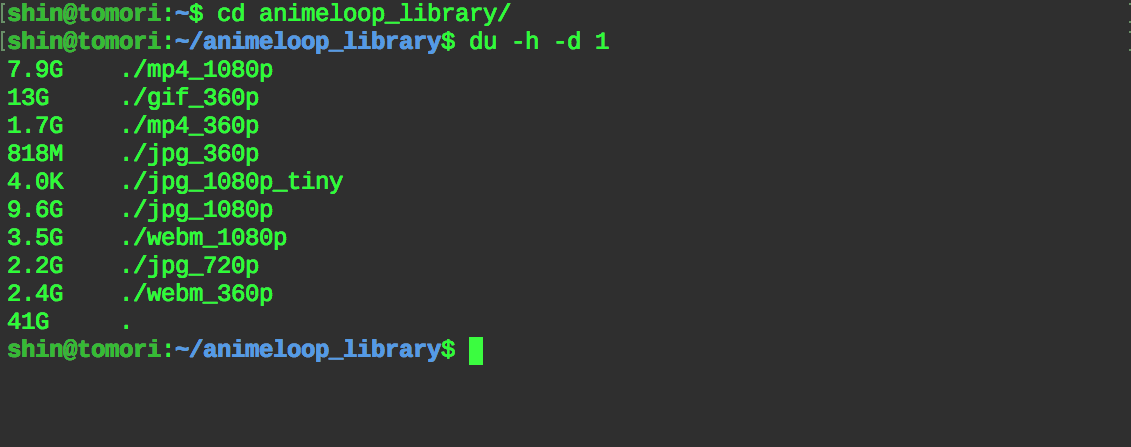
截止 2017 年 6 月 20 日,Animeloop 数据文件占用情况
可以看到,360P GIF 和 1080P JPG 文件占用了非常大的空间。GIF 还能理解,最奇葩的是 1080P JPG 存的是每个视频的封面,结果总体积比原来视频文件都还要大(9.6G jpg_1080p > 7.9G mp4_1080p)(黑人问号???.jpg
封面图片有尝试过使用 tinypng 压缩(早前数据量还不多的时候),但是由于费用昂贵等各种原因,就暂时转换了一个 720P JPG 的版本用着。
页面路由
GET /loop/:id
GET /episode/:id
GET /series/:id
GET /tags/:name (? or :id)
GET /list/series
GET /list/episodes
GET /list/tags
GET /filter
GET /about
GET /api
GET /status
RESTful API
GET /api/rand?query=xxx...
GET /api/v1/xxxxx...
前端
偷懒主义是不会自己写前端的。
一开始写这个站的时候,直接找了一个模板魔改了一番就直接用上了。(虽然现在又有一点后悔 2333)虽然问题还很多,“而且在某些前端工程师看来不够优雅”,我个人想法就是能用就行。
一般这种时候就有人会跳出来说,怎么不用 angular.js 呀,为什么不试一下新的 vue.js 呀,怎么还在用 jQuery 这种老掉牙的东西呢!
哇这页面怎么还要刷新,为什么不是 SPA,SPA 多好啊。
...
多语言
通过 whatanime.ga 可以获取到繁体中文标题和 anilist id,然后结合 Anilist API 可以获得英文的番剧数据。(已实现)
通过标题在 bangumi.tv 以及其他更多的信息站获取更多国家语言的番剧信息。(未实现)
目前网页界面上的语言已支持中文、英语和日语。
Autobot
Twitter 机器人,每天定时自动发一条随机 loop 的推文。
(持续更新中...)
数据存储的字段
只要是有的数据,哪怕是你眼里再无用的数据字段,都尽可能的往数据库里面丢。后期维护,数据太多了可以删除,但是一开始如果就没有存储数据,那么怎么后悔都来不及了。
比如,animeloop-cli 在生成 loop 的时候,会计算 hash,计算不同帧画面之间的相似度数值,这些在生成的 json 数据里是有的,但是在 server 写入到数据库的时候,当时觉得没必要,就直接丢弃到,结果现在特别的后悔。
总之一句话,数据无价。
Member discussion