为 Animeloop 生成标签
截止目前 animeloop.org 已经有 410 series, 4153 episodes, 174905 loops 这么大量的数据了。但是这些数据都还只是原始数据,没有任何的标签记录。
这次借助 illustration2vec 这个项目来给每个 loop 生成一些标签,让这些大量的数据直接相互联系、进行分类。
illustration2vec 目前由于很长一段时间没维护了,直接运行起来有点问题,有些许代码行段落需要 fix 一些,所以这里就直接 fork 了一份来修复暂时用着,项目代码仓库:https://github.com/moeoverflow/illustration2vec。
运行程序得到的原始数据(Raw Data):
[{'character': [(u'hatsune miku', 0.9999994039535522)],
'copyright': [(u'vocaloid', 0.9999998807907104)],
'general': [(u'thighhighs', 0.9956372380256653),
(u'1girl', 0.9873462319374084),
(u'twintails', 0.9812833666801453),
(u'solo', 0.9632901549339294),
(u'aqua hair', 0.9167950749397278),
(u'long hair', 0.8817108273506165),
(u'very long hair', 0.8326570987701416),
(u'detached sleeves', 0.7448858618736267),
(u'skirt', 0.6780789494514465),
(u'necktie', 0.5608364939689636),
(u'aqua eyes', 0.5527772307395935)],
'rating': [(u'safe', 0.9785731434822083),
(u'questionable', 0.020535090938210487),
(u'explicit', 0.0006299660308286548)]}]
可以看到大致上能识别出的信息有
- character
- copyright
- general
- rating -> safe(safe, question, explicit)
在存入数据库的时候可以通过多添加一个数据列来展平数据(Flap Map),数据库 Schema:
| loopid | type | value | confidence | source | lang |
|---|---|---|---|---|---|
| ObjectId | String | String | String | String | String |
{
_id: ObjectId,
loopid: ObjectId,
type: String, // ['character', 'copyright', 'general', 'safe']
value: String,
confidence: Number, //Double
source: String, // default: 'illustration2vec'
lang: String, // default: 'en'
}
简单脚本 [1]:
import os
import sys
import logging
from tqdm import tqdm
from illustration2vec import i2v
from PIL import Image
from pymongo import MongoClient
from bson.objectid import ObjectId
from config import config
# Logger configure
logging.getLogger('illus2vec')
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
logger = logging.getLogger()
IMAGES_PATH = config['images_path']
# Database initial
logger.info('Connecting to database...')
client = MongoClient("localhost", 27017)
db = client.animeloop_tags
# chainer models initial
logger.info('Loading chainer models...')
illust2vec = i2v.make_i2v_with_chainer(
config['caffemodel'], config['tag_list'])
# save tags estimated from image file into dababase
def to_tags(filename, loopid):
image = Image.open(filename)
result = illust2vec.estimate_plausible_tags([image], threshold=0.5)[0]
tag_shcema = {
'loopid': ObjectId(loopid),
'source': 'illustration2vec',
'lang': 'en'
}
# Extract tags from database to memory
# for performance optimization
saved_tags = list(db.tags.find({'loopid': ObjectId(loopid)}))
def exist_in_tagslist(loopid, type, value):
for t in saved_tags:
if str(t['loopid']) == loopid and t['type'] == type and t['value'] == value:
return True
return False
for key in result.keys():
for item in result[key]:
tag = tag_shcema.copy()
if key is 'rating':
tag['type'] = 'safe'
else:
tag['type'] = key
tag['value'] = item[0]
tag['confidence'] = item[1]
# Avoid saving duplicate data
if not exist_in_tagslist(loopid, tag['type'], tag['value']):
db.tags.insert_one(tag)
db.tagscheck.insert_one({'loopid': ObjectId(loopid)})
# performance optimization
saved_tagscheck = map(lambda tc: str(tc['loopid']), list(db.tagscheck.find({})))
logger.info('Loading files list...')
files = os.listdir(IMAGES_PATH)
logger.info('Estimating tags')
progress_bar = tqdm(files, ascii=True, dynamic_ncols=True, bar_format='{l_bar}{bar}| {n_fmt}/{total_fmt}')
for file in progress_bar:
if not os.path.isdir(file):
filename = IMAGES_PATH + '/' + file
loopid = os.path.splitext(file)[0]
ext = os.path.splitext(file)[1]
if not (ext == '.jpg' or ext == '.png'):
continue
if loopid not in saved_tagscheck:
to_tags(filename, loopid)
考虑到数据的量特别的大,在写程序生成的时候,要使用到任务队列,以多个任务并发运行的方式提高综合速度。
一开始考虑到 File I/O 的问题,实际跑程序的过程发现,大量的时间是消耗在了 i2v 识别 tags 的时候,所以就没有再考虑加入多线程并行。
最后在 Animeloop 上展示出结果:
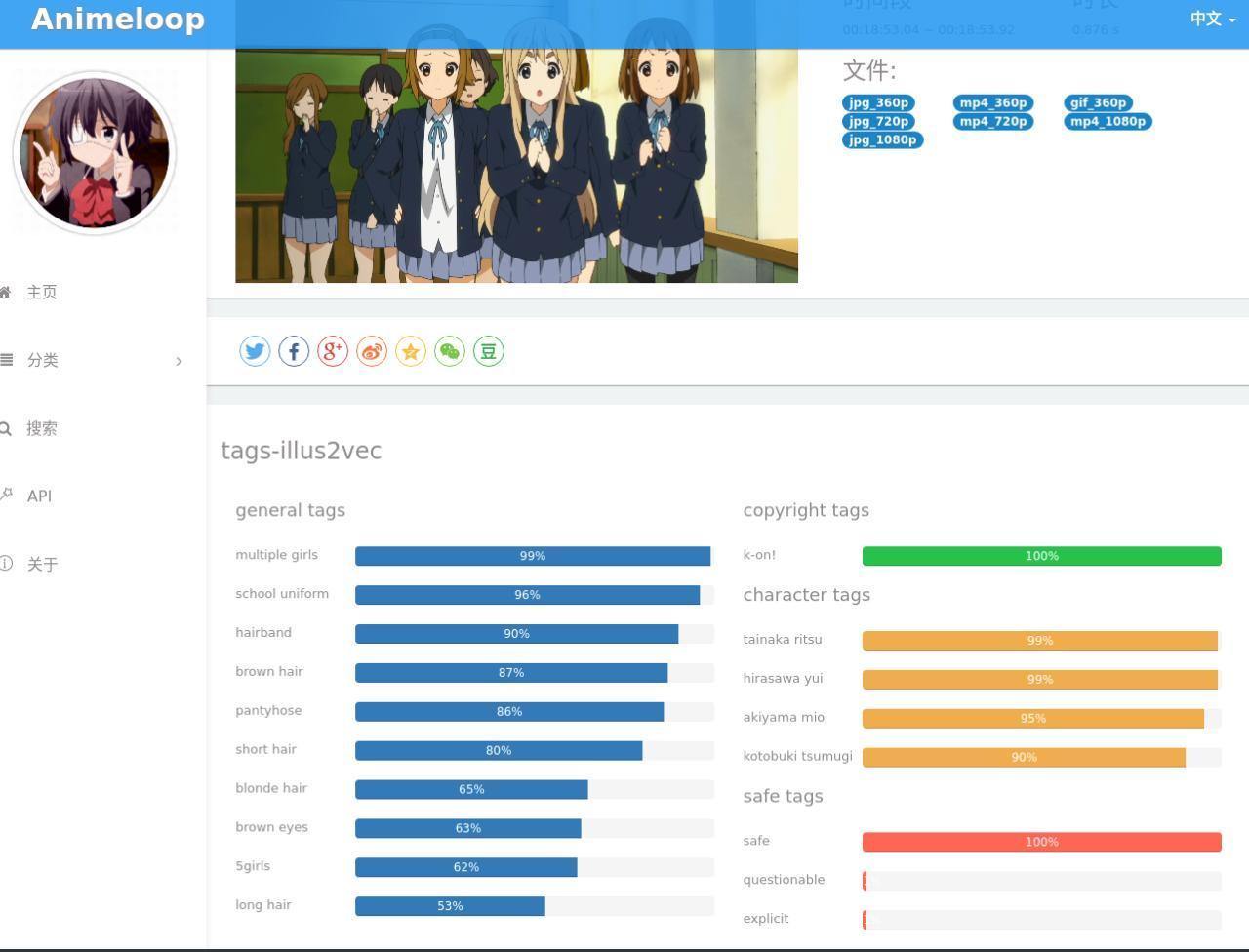
Member discussion